
I recently had a need to use OCR on an existing image, and a teamate suggested using the new Oxford APIs. This was a result of my afternoon quick hack, but rolled up into a Powershell cmdlet that could be reused by others.
Setting up the Oxford APIs for use
To quickly get up to speed, I followed the descriptions here which outline the steps as:
- Select the API you wish to use
- I navigated to Computer Vision APIs and selected the “Sign Up” button.
- This will bring up the Azure portal, select the marketplace
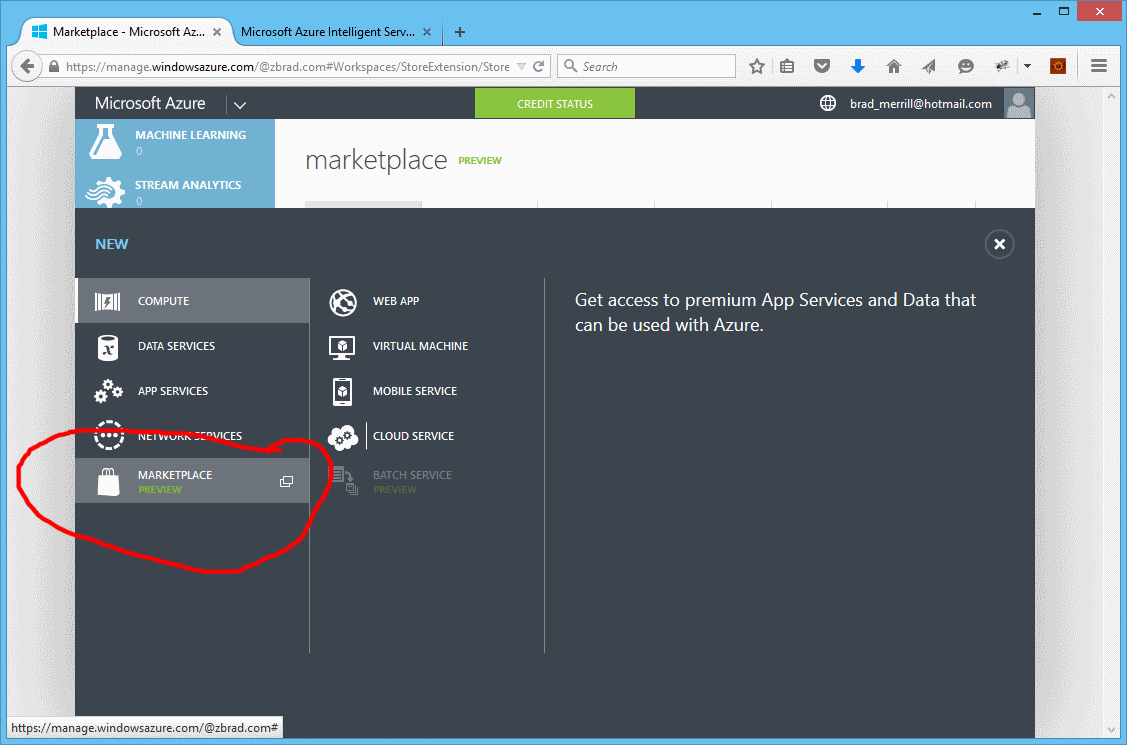 you will have to option of naming your service, I chose VisionApi
you will have to option of naming your service, I chose VisionApi
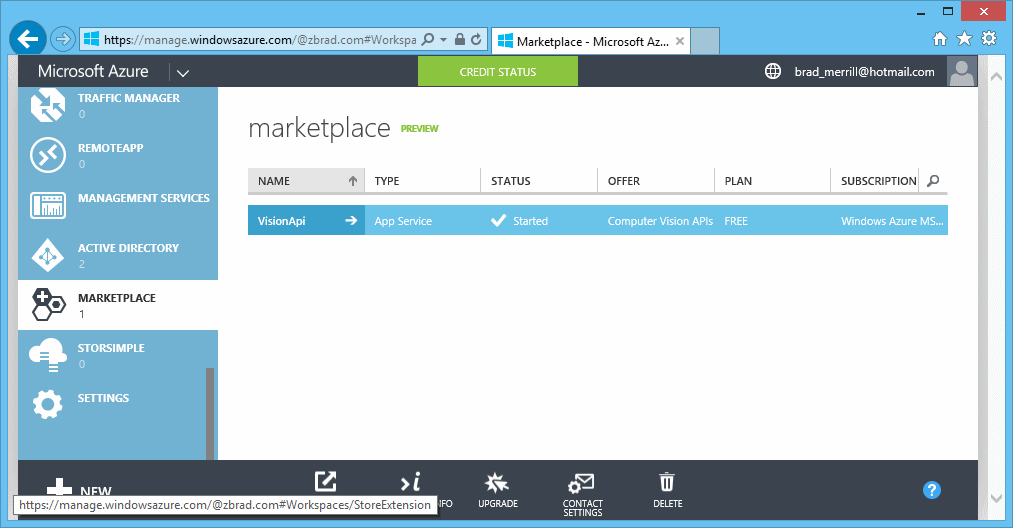 The “purchase” is free, and shows up as an Azure Marketplace offering. (Note that you may need to scroll down the listing of services in the Azure portal.
The “purchase” is free, and shows up as an Azure Marketplace offering. (Note that you may need to scroll down the listing of services in the Azure portal. - When you are presented with the “dashboard” for the marketplace, select the “Manage” option
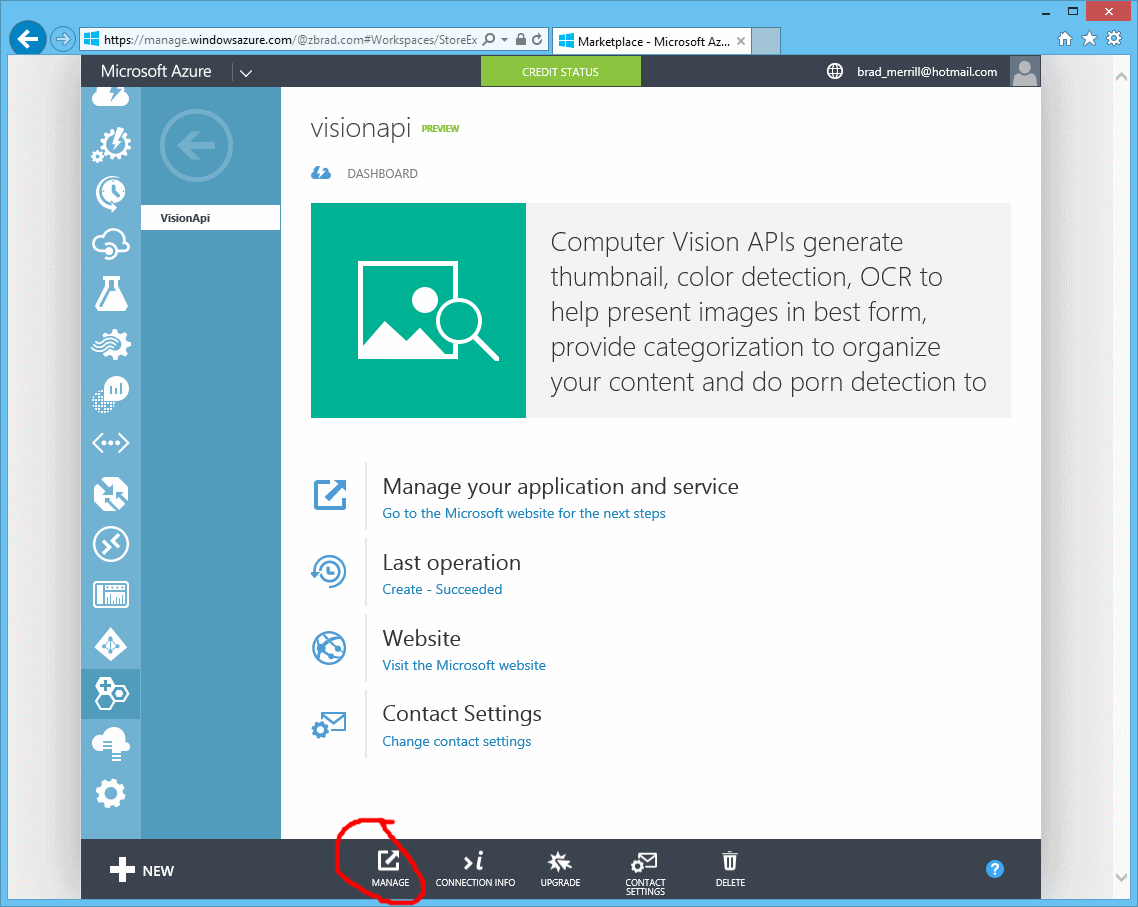
-
You will now see your subscriptions with key information hidden. Select Show and copy your new OxfordKey.
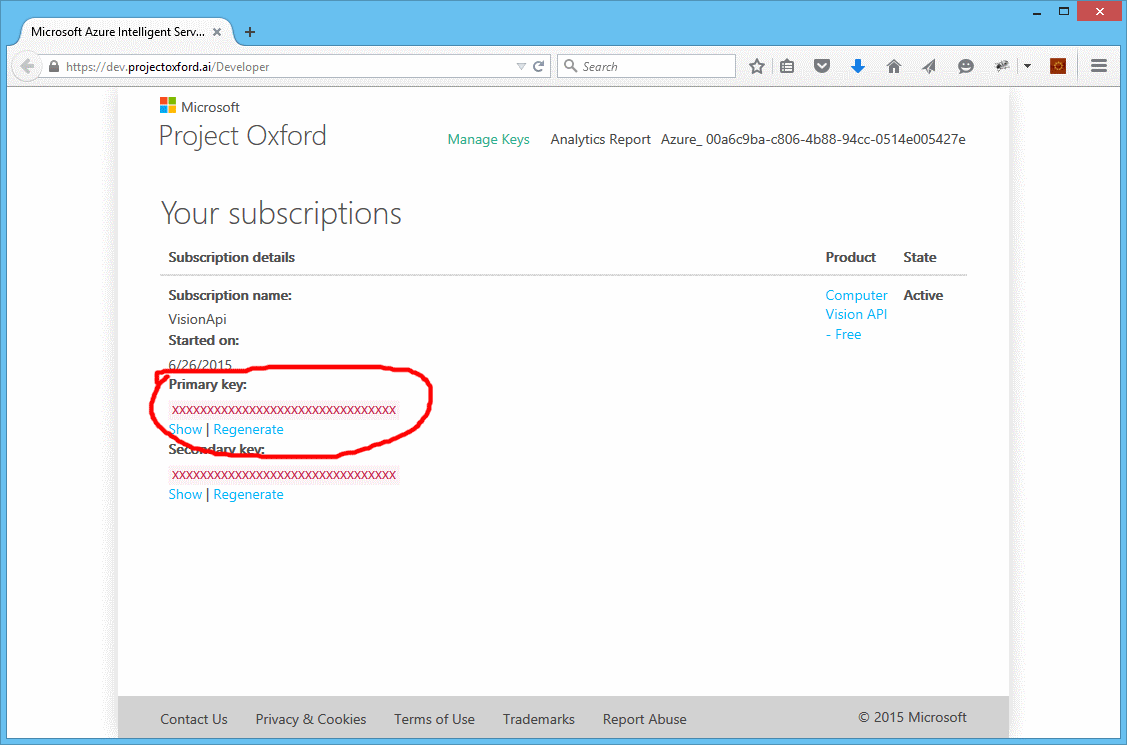
Now that we have the service side setup, we will use the Oxford.ps1 script from psoxford. Easiest way to get this is to clone the repo, which will also get you our test images.
PowerShell
Setup
- Launch a powershell session (I prefer to use the Windows PowerShell ISE.
- Navigate to your clone
- Import the script and set your key
. .\Oxford.ps1
$key = 'put your oxford key here'
Single File
We can now call the Oxford OCR and get results:
$image = '.\images\ifwedid.jpg'
Get-Text -Image $image -OxfordKey $key
which altogether when run:
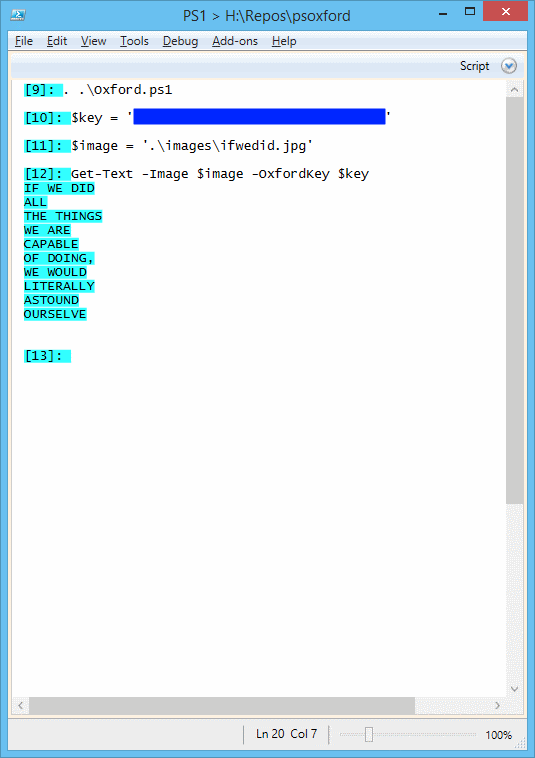
Multiple Files
That’s fine for a single file, but what if we want all the files in a folder? PowerShell to the rescue:
$files = Get-ChildItem .\images | % { $_.FullName }
$files | Get-Text -OxfordKey $key
In this case PowerShell will call Get-Text cmdlet for each file in the folder.
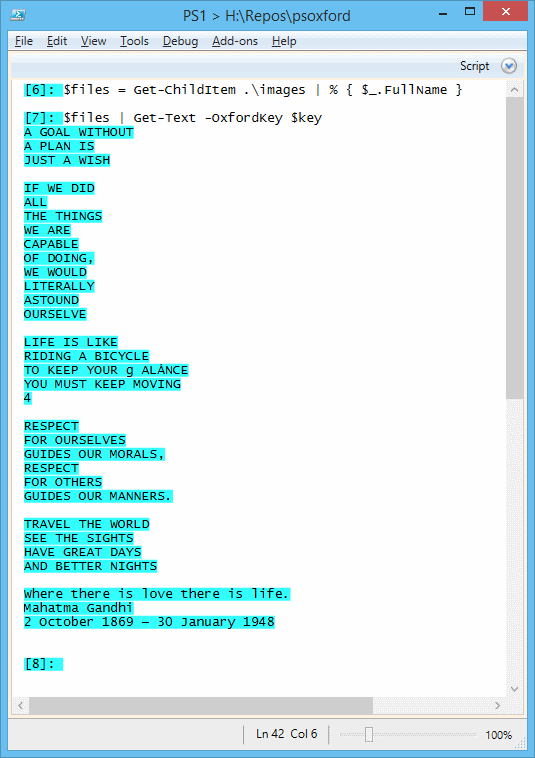
A Brief Look At The Script
The file Oxford.ps1 defines 2 cmdlets:
- Get-Text
- Invoke-Oxford
The Get-Text cmdlet requires 2 mandatory parameters Image and OxfordKey. The function is declared as:
function Get-Text
{
[CmdletBinding()]
Param(
[Parameter(Mandatory=$true,ValueFromPipeline=$true)]
[string] $Image,
[Parameter(Mandatory=$true)]
[string] $OxfordKey
)
By allowing the Image parameter to be obtained from the pipeline, we enable the multi-file scenario. The body of the function simply calls the Invoke-Oxford cmdlet, and then combines the text results for output.
The declaration of the Invoke-Oxford cmdlet is:
function Invoke-Oxford
{
[CmdletBinding()]
Param(
[Parameter(Mandatory=$true)]
[string] $OxfordKey,
[string] $Api,
[string] $Lang = 'en',
[string] $Detect = $true,
[string] $InFile
)
Summary
This was a brief afternoon hack to see if the Oxford OCR Api would be useful in my project. Unfortunately for myself it was not, however if this description and scripts helps others to determine that utility for themselves, it was worthwhile.